你的 AI 聊天界面为什么卡?Midjourney 团队的答案,可能改变整个前端文本渲染
· 3 min read ·
canvas pretext
如果你最近在做 AI 相关的前端项目,大概率遇到过这个场景:
用户发了一条消息,大模型开始流式返回。Token 一个接一个地蹦出来,你需要实时把它们追加到聊天气泡里。看起来很简单对吧?
但你很快发现界面开始抖动。气泡高度一变,下面的消息全部要重新排列,滚动条跳来跳去。如果同时有好几条消息在流式返回——比如多轮对话的重新生成——整个页面直接掉帧。
问题出在哪?不是你的代码写得烂,是浏览器的文本测量机制本身就不是为这个场景设计的。
每次你想知道”这段文字渲染出来有多高”,传统做法只有一条路:把文本塞进 DOM,让浏览器跑一遍 layout,然后读 offsetHeight。这个过程叫 reflow——它是同步的、阻塞的,而且在文本量大的时候开销很大。
一条消息还好。但 AI 时代的聊天界面,一秒钟可能有几十个 token 到达,每个 token 都可能导致换行、改变高度。每次变化都要 reflow 一遍,内容越多越可能造成页面的卡顿。
Midjourney 的前端团队遇到了同样的问题。他们的解法,最终变成了一个叫 Pretext 的开源库。
Pretext 的作者是 Cheng Lou——如果你写过 React 动画,大概用过他写的 react-motion。他之前在 Meta 的 React 核心团队,现在在 Midjourney 做前端。
Pretext 的核心思路只有一句话:用 Canvas 的 measureText() 预先读取每个字符的宽度,然后只靠加减乘除就能算出文本在任意容器宽度下的换行位置和总高度。
整个过程不碰 DOM,不触发 reflow。
import { prepare, layout } from '@chenglou/pretext'
// 阶段 1:prepare — 只需做一次// 内部用 Canvas measureText 测量每个字的宽度,缓存起来const prepared = prepare(text, '16px "Inter"')
// 阶段 2:layout — 纯算术,可以反复调用// 给定容器宽度和行高,算出文本的总高度和行数const result = layout(prepared, 300, 24)// => { lineCount: 5, height: 120 }关键区别:
prepare 会调用 Canvas API,有一定开销(约 17ms/500 段文本),但只需要做一次layout 是纯粹的加减乘除,不碰任何浏览器 API——约 0.1ms/500 段文本你没看错,layout 阶段比 DOM reflow 快几百倍。
这意味着什么?当用户把窗口从宽拖到窄,你的虚拟列表需要重新计算每条消息的高度。传统方式要对每条消息做一次 reflow;用 Pretext,prepare 的结果还在缓存里,只需要在新宽度上重新跑一遍 layout——几乎零成本。
我拿 500 段文本在 10 个不同宽度下反复测量高度(模拟窗口 resize),结果是这样的:

5000 次测量,DOM reflow 约 120 ms,Pretext layout 约 6 ms。prepare 的一次性开销(约 54 ms)另算——它只跑一次,之后不管重新 layout 多少次都是纯算术。
prepare + layout 适合”我只想知道高度”的场景。但 Pretext 还暴露了逐行布局的 API,能做更有意思的事情。
layoutNextLine 每次算一行,关键在于:每行可以给不同的宽度。这意味着文本可以绕过任意形状流动。
const prepared = prepareWithSegments(text, '16px "Inter"')let cursor = { segmentIndex: 0, graphemeIndex: 0 }let y = 0
while (y + lineHeight <= canvasHeight) { // 这一行有多宽?取决于障碍物在这个 y 位置占了多少空间 const availableWidth = getAvailableWidth(y, obstacle) const line = layoutNextLine(prepared, cursor, availableWidth) if (!line) break
ctx.fillText(line.text, x, y) cursor = line.end y += lineHeight}我用这个 API 做了一个文本环绕的 demo:一段中英文混排实时绕过一个可拖拽的圆形。拖动过程中全程 60fps,因为每帧的 layout 只需要零点几毫秒。

这类效果在 Canvas 白板和设计工具里很常见(tldraw 已经集成了 Pretext 来做文本框 resize)。传统的做法是维护一个隐藏的 DOM 镜像来测量,而现在一个纯函数就解决了。
Pretext 不是一个所有项目都需要的库。如果你的页面就是几段静态文本,浏览器的 layout 引擎工作得很好,没必要引入它。
但如果你在做这些事情,它可能值得认真考虑:
react-virtualized 的 variable-height rows 一直是痛点。Pretext 让你在挂载前就精确知道每行高度。更深层地看,Pretext 让文本布局变成了一个纯函数:(text, font, width) → dimensions。它不依赖 DOM,意味着将来可以在 Web Worker 里跑,可以做预测性 UI,可以完全脱离浏览器主线程。这是一个架构层面的解耦。
Pretext 解决了文本测量的问题。但还有另一个长期困扰 Canvas 应用的问题:Canvas 画不了 HTML。
如果你在 Canvas 上需要显示一段带样式的文本——渐变色、圆角边框、阴影、自定义字体——你只能手动用 Canvas API 一笔一笔描。或者用 html2canvas 这类库,但它们的本质是用 JavaScript 重新实现 CSS 渲染引擎——永远不可能完整支持所有 CSS 属性。
这在 AI 产品中也是个很现实的问题。越来越多的 AI 应用需要视觉化呈现——Claude 的 Artifacts 可以渲染 HTML 预览,v0 直接生成 UI 组件。如果你想对这些 HTML 内容做 Canvas 级别的操控(变换、混合、导出为图片),目前没有好的办法。
Google 的 Chromium 团队提出了一个正在实验中的方案:直接让浏览器把真实的 HTML 渲染进 Canvas。
这个提案叫 HTML-in-Canvas,目前在 WICG(Web Incubator Community Group)孵化。核心 API 是 drawElementImage():
<canvas id="canvas" layoutsubtree> <!-- 这是一个真实的 DOM 元素,放在 canvas 内部 --> <div id="card" style="background: linear-gradient(135deg, #6366f1, #8b5cf6); border-radius: 16px; padding: 24px; color: white;"> <h2>Hello from HTML</h2> <p>带渐变、圆角、完整 CSS 样式</p> <input type="text" placeholder="我还能输入文字..." /> </div></canvas>
<script>const ctx = canvas.getContext('2d')// 浏览器自己渲染这个 HTML 元素,画进 canvasctx.drawElementImage(card, 100, 50)</script>关键点:
layoutsubtree 属性让 canvas 的子元素参与布局,但默认不可见drawElementImage() 让浏览器自己把这个元素渲染进 canvas——不是 JS 重新实现 CSS,而是浏览器的原生渲染管线<input> 还能正常输入——它是真实的 DOM 元素,保留了可访问性和交互性关键洞察:着色器可以拿到 HTML 的渲染像素了。
这意味着你可以对任何 HTML 内容做 Canvas/WebGL 级别的操控——非平面渲染(把 HTML 贴到 3D 物体上)、自定义混合过渡(亮暗主题逐像素 blend)、录屏导出(直接送 VideoEncoder)。这些以前在 DOM 世界做不到,在 Canvas 世界又画不出 HTML。
我写了一个 demo:把一张带 CSS 渐变、圆角、输入框的卡片通过 drawElementImage() 画进 Canvas,然后做波浪扭曲——按水平条带切割,每条加正弦偏移:
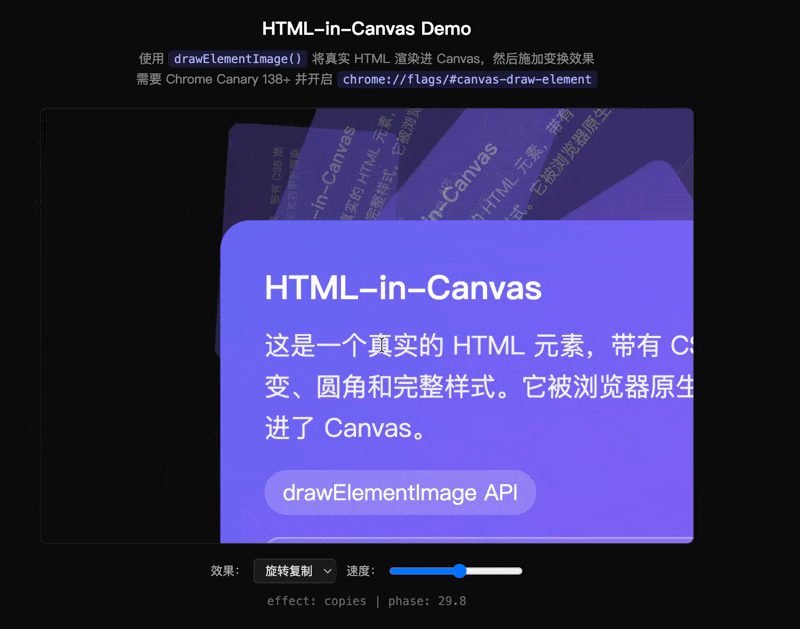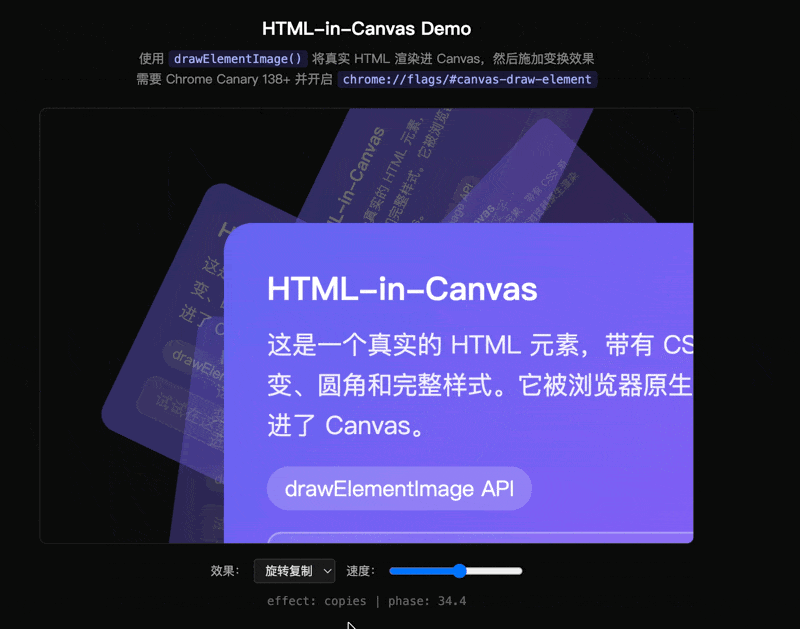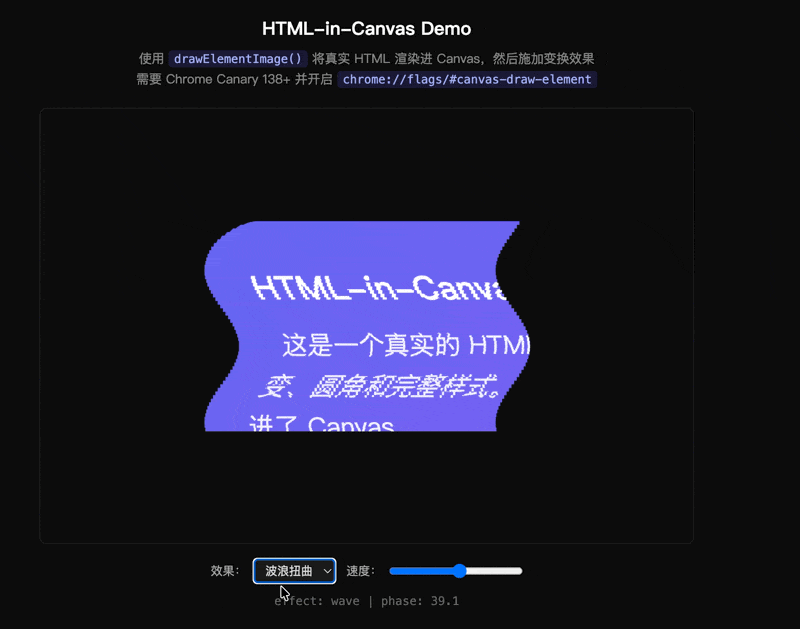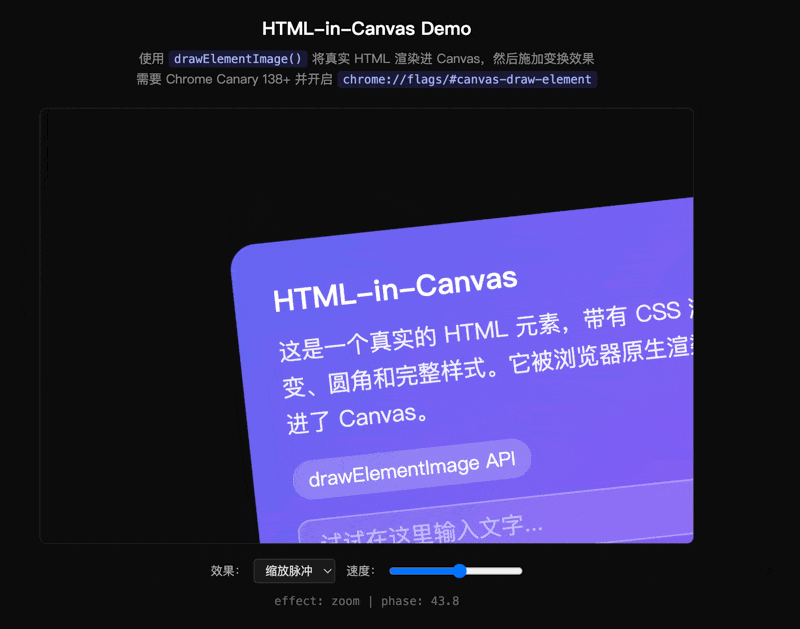
这种逐像素的形变在 DOM 里无法实现。而 Canvas 以前又渲染不了带完整 CSS 样式的 HTML。drawElementImage 打通了两个世界——而且卡片里的 input 还能打字,因为它始终是真实的 DOM 元素。
目前 这个 API 目前还非常早期:
chrome://flags/#canvas-draw-element 体验所以它现在不能用于生产。但方向感很明确:浏览器应该提供原生能力把 HTML 渲染进 Canvas,而不是让开发者用 JS 重新发明轮子。这个提案值得持续关注。
现在我们可以看到一幅更完整的图景:
Pretext 解决了「测量」:Canvas 应用不再需要 DOM 来算文本尺寸。
HTML-in-Canvas 解决了「渲染」:Canvas 不再需要 JS 来山寨 HTML 渲染。
它们不是竞品,而是拼图的两块——共同指向一个方向:Canvas 应用正在获得原本只有 DOM 才有的文本和渲染能力,而且性能更好、控制力更强。
回想一下 Figma 当年为什么要花大力气自建渲染引擎?因为浏览器不给它需要的能力。现在这些能力正在以原生 API 的形式回到浏览器。未来的 Canvas 应用——无论是下一个 Figma、下一个 tldraw,还是下一个 AI 产品的富交互界面——可能不再需要从零搭建「浏览器中的浏览器」。
根据你的场景选择:
如果你在做 AI 聊天/流式文本界面
→ 现在就试试 Pretext。npm install @chenglou/pretext,重点看 prepare + layout 两个 API。对虚拟列表的优化效果可能会让你惊喜。
如果你在做 Canvas 应用(白板、编辑器、设计工具) → Pretext 已经可以解决文本测量问题(tldraw 是现成案例)。HTML-in-Canvas 持续关注,等它进入 Origin Trial 再评估。
如果你在做 HTML 截图/导出(社交卡片、分享图)
→ 短期继续用 html2canvas 或 Snapdom。长期 drawElementImage 会是更好的答案。
参考链接